

A introdução dos modelos de linguagem grande (LLMs) revolucionou várias aplicações no campo do processamento de linguagem natural. Esses modelos, no entanto, enfrentam desafios inerentes que afetam sua eficácia. Devido à falta de fontes de conhecimento, sua natureza estática e a falta de conhecimento específico do domínio limitam sua aplicabilidade em contextos dinâmicos.
Recentemente, os times de pesquisa desenvolveram uma solução conhecida como Retrieval Augmentation Generation (RAG) para resolver esses problemas. O RAG combina a recuperação de fontes de conhecimento específicas e de alta qualidade com os recursos generativos de modelos, como o ChatGPT, para aumentar a precisão e a relevância do contexto.
Esta postagem do blog explora a importância da RAG, seus componentes, os critérios para selecionar fontes de conhecimento e a função de plataformas como a StackSpot AI na integração dessas fontes. Desse modo, o objetivo é esclarecer os recursos aprimorados e as possíveis aplicações de LLMs aprimorados por RAG em vários domínios.
Desafios do uso de LLMs
A princípio, os modelos de linguagem de uso geral executam tarefas cotidianas, como análise de sentimentos e reconhecimento de entidades nomeadas. Normalmente, essas tarefas não exigem conhecimento contextual adicional.
No entanto, quando é necessário conhecimento adicional, esses modelos de linguagem grandes (LLMs) apresentam duas desvantagens significativas:
- São estáticos: os LLMs são “congelados no tempo” e não possuem informações atualizadas.
- Não têm conhecimento específico do domínio: os LLMs são treinados com dados públicos, o que significa que eles não conhecem os dados privados de sua empresa.
Infelizmente, esses problemas afetam a precisão dos aplicativos que utilizam LLMs.
O que é o Retrieval Augmentation Generation (RAG)?
Para tarefas mais complexas e que exigem muito conhecimento, os pesquisadores da Meta AI introduziram um método chamado Retrieval Augmentation Generation (RAG) para lidar com esses tipos de tarefas, ajudando a atenuar o problema da “alucinação”.
No entanto, a eficácia dos sistemas baseados no Retrieval Augmentation Generation (RAG) depende do estabelecimento de fontes de conhecimento de alta qualidade.
As fontes de conhecimento são documentos representativos que aprimoram o componente gerador dos sistemas RAG. Essas fontes são fundamentais para fornecer a profundidade e a amplitude necessárias de informações, permitindo que esses sistemas forneçam conteúdo enriquecido e contextualmente relevante que atenda às demandas diferenciadas das pessoas usuárias.
Como funciona o Retrieval Augmentation Generation (RAG)?
Em resumo, para implementar um Retrieval Augmentation Generation (RAG), devemos dividi-lo em dois componentes principais: os componentes de recuperação e de geração.
Componente de recuperação
Esse componente obtém informações relevantes de um conjunto de dados específico. Normalmente, esses componentes usam técnicas de recuperação de informações ou pesquisa semântica para identificar os dados mais relevantes para uma determinada consulta. Eles são eficientes na obtenção de informações relevantes, mas não podem gerar novos conteúdos.
Componente generativo
Por outro lado, os componentes generativos criam um novo conteúdo com base em um determinado prompt. Por exemplo, modelos de linguagem como o ChatGPT são excelentes para esse tipo de tarefa.
Para que o componente de recuperação funcione de forma eficaz é essencial identificar e selecionar fontes de conhecimento representativas. Elas consistem em documentos retidos pelo componente de recuperação, que posteriormente servem de base para o resultado do componente gerador.
A qualidade dessas fontes afeta diretamente a qualidade das respostas geradas. Dessa forma, fontes de conhecimento precisas, atuais e abrangentes garantem que as informações recuperadas sejam relevantes e confiáveis, permitindo que o componente gerador produza respostas bem informadas e precisas.
Por que é importante ter fontes de conhecimento representativas?
A base das fontes de conhecimento é o alicerce de qualquer sistema robusto de recuperação e processamento de informações. A integridade e a utilidade desses sistemas dependem da qualidade e da representatividade das informações que eles utilizam.
As fontes de conhecimento representativas garantem que os dados não sejam apenas pertinentes e confiáveis, mas também reflitam a natureza multifacetada do mundo real. Portanto, as fontes permitem o fornecimento de insights precisos, abrangentes e aplicáveis aos cenários atuais.
Em essência, a seleção de fontes de conhecimento representativas é um determinante crucial da capacidade de um sistema de fornecer respostas relevantes, confiáveis e diferenciadas, o que é indispensável para aplicativos baseados em LLM.
Critérios para selecionar fontes de conhecimento representativas
Aqui, compilamos uma lista de itens com o objetivo de ajudar devs a criarem seus aplicativos baseados em LLM e orientar pessoas usuárias de tais sistemas para maximizar seus benefícios.
Aliás, esses itens selecionados garantem uma experiência ideal no aproveitamento dos recursos dos modelos de linguagem.
Relevância
Uma fonte de conhecimento relevante está intrinsecamente ligada ao domínio específico ao qual se destina. Considere, por exemplo, a tarefa de desenvolver software para gerenciamento de projetos.
Nesse cenário, uma fonte de conhecimento que contenha os artigos mais recentes, estudos de caso e práticas recomendadas em metodologias ágeis, gerenciamento do ciclo de vida do software e ferramentas de produtividade da equipe seria inestimável.
A relevância é fundamental para garantir que os dados recuperados sejam exatamente o que é necessário para o contexto do software. Assim, aumenta-se o foco e a eficácia do resultado gerador no fornecimento de respostas práticas.
Abrangência
Uma fonte de conhecimento abrangente oferece ampla cobertura de assuntos, incluindo vários subtópicos, opiniões e avanços recentes.
Por exemplo, ao criar um algoritmo para processamento de linguagem natural (PLN), uma base de conhecimento abrangente não só cobriria as técnicas fundamentais de PLN, mas também se aprofundaria em tópicos avançados. Como análise de sentimentos, tradução automática e reconhecimento de fala, incluindo as metodologias de pesquisa mais recentes.
Assim, essa amplitude garante que as informações recuperadas sejam detalhadas e forneçam uma visão holística do tópico.
Atualidade
A atualidade das fontes de conhecimento diz respeito ao frescor e à atualidade das informações, o que é particularmente crucial em campos de rápida evolução, como o desenvolvimento de software.
Por exemplo, ao desenvolver um aplicativo de segurança cibernética, as fontes de conhecimento precisam incluir as vulnerabilidades mais recentes.
Precisão
A precisão é fundamental para a confiabilidade de qualquer fonte de conhecimento, pois garante informações precisas e submetidas a uma verificação minuciosa em relação a padrões de referência estabelecidos. No desenvolvimento de software, por exemplo, a precisão é fundamental na criação de um sistema de software financeiro.
Sem preconceitos
Por fim, uma fonte de conhecimento livre de preconceitos é essencial para transmitir informações objetivas, sem preconceitos pessoais ou culturais.
Dessa forma, no desenvolvimento de software, considere a criação de um mecanismo de recomendação. Ao garantir que os dados não sejam influenciados por pontos de vista ou preferências específicas, o mecanismo de recomendação pode oferecer opções justas, equilibradas e que reflitam uma gama diversificada de experiências.
Fontes de conhecimento na StackSpot AI
A StackSpot AI apresenta uma interface fácil de usar, projetada para carregar fontes de conhecimento pertinentes sem problemas. Essa interface tem um mecanismo de consulta avançado que aproveita técnicas sofisticadas de recuperação de informações para localizar documentos com eficiência.
A figura abaixo mostra o recurso do portal para carregar fontes de conhecimento.
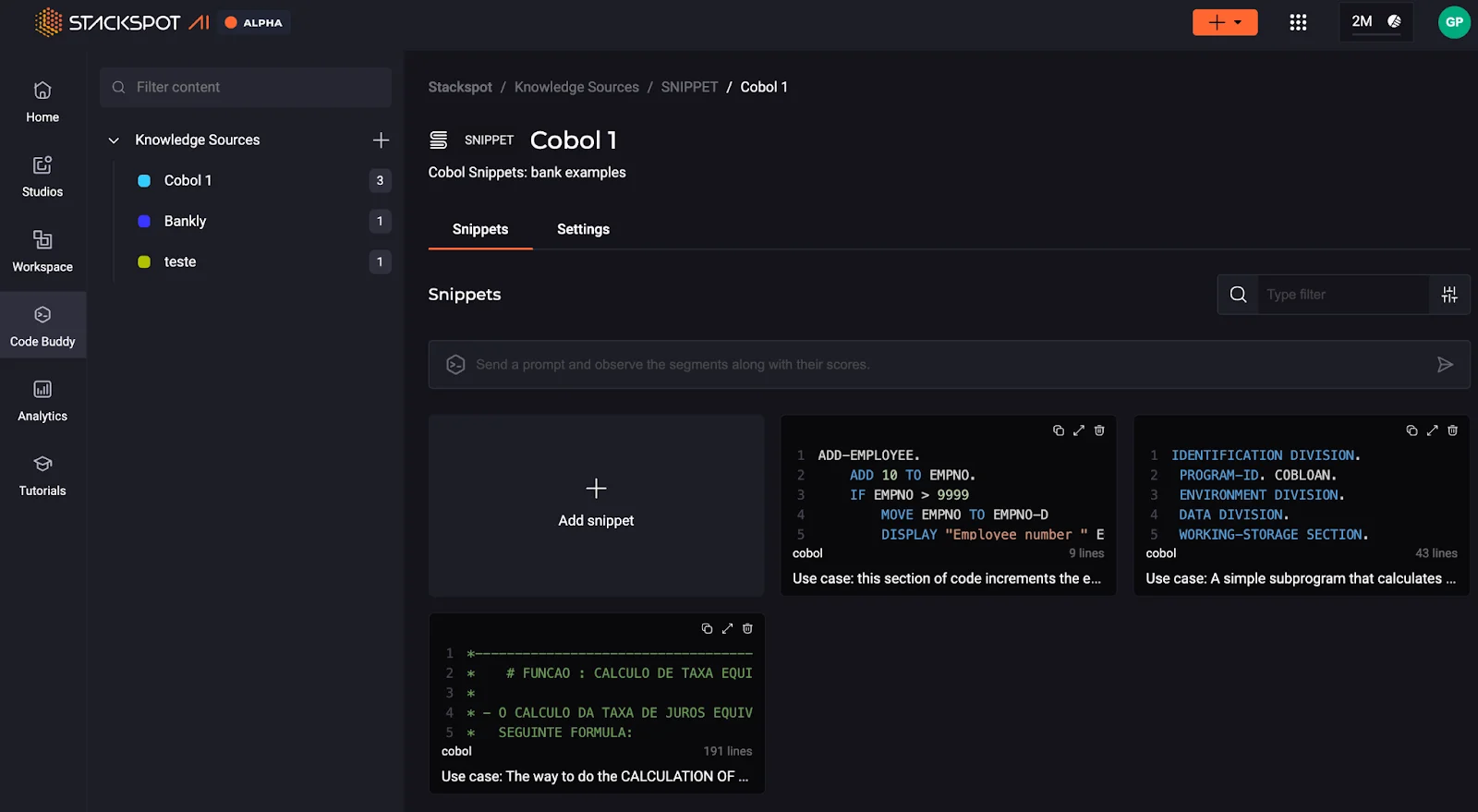
Uma vez que um conjunto diversificado de fontes de conhecimento é integrado ao portal, o Plugin StackSpot AI permite que as pessoas usuárias executem suas consultas por meio de prompts. Isso é feito sem a necessidade de estar ciente das fontes de conhecimento específicas à sua disposição.
Essencialmente, o Plugin inclui um mecanismo de pesquisa avançado que combina de forma inteligente as consultas dos usuários com as fontes de conhecimento mais relevantes.
Por exemplo, quando uma consulta como “criar um método de pagamento” é inserida, o mecanismo procura e alinha a consulta com as fontes de conhecimento apropriadas.
Essas fontes podem variar de uma classe Java que detalha o procedimento de implementação de um método de pagamento a uma API que facilita a conexão com um serviço de pagamento.
Por meio desse processo intuitivo e eficiente, a plataforma garante que os usuários possam acessar e utilizar com facilidade e precisão a riqueza de informações armazenadas no sistema.
Conclusão
O sucesso dos aplicativos baseados em modelos de linguagem, especialmente aqueles que exigem uma compreensão diferenciada de assuntos complexos, depende muito da qualidade de suas fontes de conhecimento subjacentes.
À medida que navegamos no cenário em constante evolução do desenvolvimento de software e da análise de dados, os princípios de relevância, abrangência, atualidade, precisão e ausência de viés formam os pilares sobre de sistemas Retrieval Augmentation Generation (RAG) eficazes e confiáveis.
Com a curadoria meticulosa dessas fontes de conhecimento, tanto as pessoas desenvolvedoras quanto as usuárias podem aproveitar todo o potencial dos modelos de linguagem. Dessa forma, garantindo que o resultado seja não apenas informativo e relevante, mas também um reflexo dos dados mais recentes e precisos disponíveis.
Esperamos que tenha gostado do conteúdo! Caso tenha alguma dúvida, comente abaixo!








