
 Skip to content
Skip to content
Generative artificial intelligence — especially in the form of large language models, or LLMs — is reshaping how companies operate. But with a growing ecosystem of available options, how do you determine which model best suits your business needs?
The decision between open source or proprietary models has taken center stage, particularly after the buzz sparked by Chinese LLM DeepSeek. This article explores the nuances of each approach, highlighting often-overlooked factors that can influence your strategy.
What are LLMs?
Large Language Models (LLMs) are complex artificial intelligence systems based on deep neural networks. Trained on massive datasets, these models learn linguistic patterns, which enables them to generate text, answer questions, and write code with impressive fluency.
They rely on transformer architecture, which processes information in parallel and captures intricate contextual relationships across text.
Open Source or Proprietary: What Sets LLMs Apart?
The fundamental distinction between open source and proprietary models lies in their level of transparency.
Open source LLMs give users access to the model’s underlying code. This openness provides the freedom to audit, adapt, and fine-tune the LLM for specific use cases. Popular open source options include Llama, MPT, Falcon, Qwen, Mistral, Yi, Mixtral, Phi-2, DeciLM, and most recently, DeepSeek.
Proprietary LLMs, by contrast, are developed by private organizations that restrict access to source code. These models often offer convenience, enterprise-grade support, and frequent updates — though they come with limitations in customization. Examples of proprietary LLMs include ChatGPT, BARD, PaLM 2, Claude 2, Grok, and Gemini.
The diagram below highlights both types of models by release timeline and parameter count:
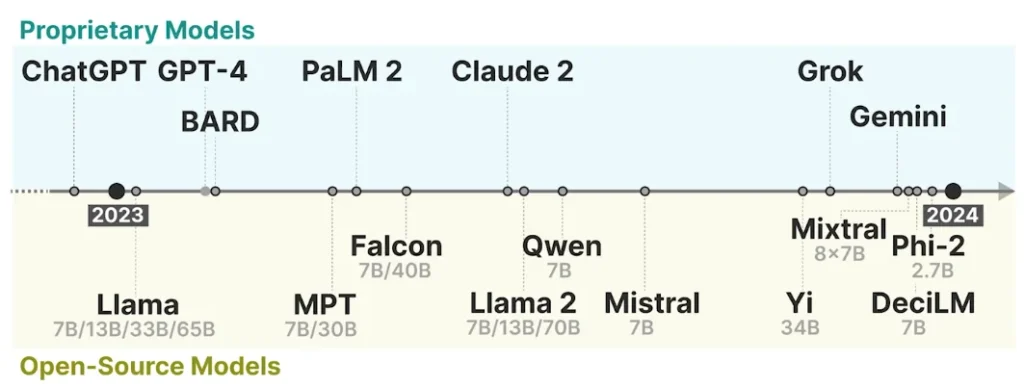
Caption: Leading open source and proprietary models currently on the market. Source: DeepLearning.ai
But the difference goes beyond just code access. Let’s explore what makes open source LLMs uniquely adaptable — and when each model type might be the right fit.
What’s Included in an Open Source Model?
Open source LLMs offer a high degree of visibility and flexibility, especially when it comes to personalization and optimization. Their core components typically include:
Complete Source Code
Everything from model architecture to optimization logic can be accessed, enabling teams to study and modify the model’s structure. This provides a detailed view of how the LLM is built and how it interprets data.
Training Data (Where Available)
Some projects share their datasets or document the training process in detail, allowing for quality control, bias assessment, and reproducibility. However, this is rare due to data privacy and volume constraints.
Model Weights
These are the numeric parameters the model adjusts during training. Weights define how the LLM understands relationships and patterns in the data set. Each one of them encodes the strength of connections within the neural network and is crucial to the model’s performance.
Detailed Architecture
Covers model depth (number of layers), embedding size, and hyperparameters. This enables reproducibility and performance fine-tuning.
Training Process
Includes details on computational resources (including hardware), optimization methods, and training metrics — crucial for replicating or improving the model.
Algorithms and Techniques
Information about how the model handles input, augments data, and applies regularization is vital for practical use and innovation.
Community and Documentation
Strong communities often support open source efforts, offering insights, fixes, and plugins. What’s more, comprehensive, accessible technical documentation accelerates onboarding and deployment of the model.
Key Differences Between Open Source and Proprietary LLMs
To choose the right model, one must consider more than source code. Trust, flexibility, cost, and support all weigh into this decision. Let’s break down how the two approaches compare across these four critical dimensions:
1. Transparency and Trust
- Open Source: Allows audits and in-depth analysis, making it a strong fit for teams that require oversight and explainability.
- Proprietary: Operates like a black box. While reliable, its lack of transparency can hinder accountability in regulated industries.
2. Personalization and Customization
- Open Source: Easier to tailor to domain-specific tasks. It is especially useful in fields like healthcare, law, and engineering, where terminology is domain-specific.
- Proprietary: Prioritizes ease of use but restricts how much the underlying system can be altered—updates and feature sets are controlled by the vendor.
3. Costs and Resources
- Open Source: While licensing is free, deploying these models requires significant infrastructure and technical expertise.
- Proprietary: Typically involves usage fees (e.g., token-based pricing) but bundles in support, scalability, and system reliability.
4. Support and Security
- Open Source: Community-driven support can be robust, but lacks service-level agreements (SLAs).
- Proprietary: Includes guaranteed support, regular security patches, and enterprise-grade SLAs.
Choosing the Right LLM for Your Business
The strategic decision between an open source model and a proprietary model can directly impact your results. However, there’s no one-size-fits-all answer. Each option has its place depending on business goals, technical maturity, and regulatory demands. With that in mind, let’s take a look at how you can determine which path best suits your use case.
When Open Source Makes Sense
- Research and Innovation: Ideal for universities, startups, and R&D teams that need full control to experiment.
- Specialized Applications: When tasks demand niche vocabularies or workflows, the ability to customize is essential.
When Proprietary is the Better Fit
- Mission-Critical Systems: For enterprises that cannot afford downtime or require rigorous compliance.
- Plug-and-Play Integration: Proprietary models often integrate more easily with enterprise platforms, saving time and money.
A Hybrid Model May Offer the Best of Both Worlds
Choosing between open and closed LLM architectures doesn’t have to be binary. Many companies are pursuing hybrid strategies that combine the innovation and transparency of open source models with the robustness and support of proprietary models. This strategy can offer businesses the ideal balance between personalization and reliability.
Hybrid systems often orchestrate multiple LLMs alongside smaller models — known as Small Language Models (SLMs), designed for edge computing, cost optimization, or narrow use cases.
In a highly competitive landscape, the ability to integrate and manage various models can turn AI into a long-term competitive advantage. According to CB Insights, 94% of surveyed companies now use more than one provider in their LLM stack—citing benefits like cost efficiency, specialization, and reduced vendor lock-in.
StackSpot AI: A Flexible LLM Platform
StackSpot AI defaults to OpenAI’s ChatGPT models, but it doesn’t stop there. It offers the flexibility to integrate a variety of other models — both open source or proprietary — within the same environment.
The platform supports intelligent orchestration across multiple models (both LLM and SLM) and allows AI agents to collaborate using different underlying systems. This enables tailored experiences for each use case or department.
Conclusion
Whether you opt for open source transparency or proprietary convenience, choosing the right language model requires strategic consideration. Your final decision should align with your business goals, technical maturity, and compliance landscape.
Considering elements such as cost, security, and support can help you determine which model best meets your demands. Ultimately, a hybrid strategy may offer the optimal path forward — leveraging the strengths of both ecosystems while minimizing their limitations.
Now we’d like to hear from you. What type of model are you considering for your organization? Share your thoughts or questions in the comments!
References
- 10 LLMs (Large Language Models) Open-Source Para Uso Comercial – Data Science Academy
- 8 principais LLMs de código aberto para 2024 e seus usos | DataCamp
- Uma introdução aos Large Language Models | by Nelson Frugeri, Jr | Medium
- How Transformer LLMs Work – DeepLearning.AI
- The foundation model divide: Mapping the future of open vs. closed AI development – CB Insights Research
- Should enterprises adopt closed-source or open-source AI models? – CB Insights Research



