
 Ir para o conteúdo
Ir para o conteúdo
Transformar os dados vindos de logs em decisões é um desafio recorrente. Seja pelo volume, formato das informações ou mesmo dificuldade de cruzamento, o fato é que para times é um esforço considerável. Porém, a Inteligência Artificial Generativa pode apoiar neste processo. Neste artigo, mostro como criei um Analisador de Logs com Splunk integrado à StackSpot AI.
Para isso, eu usei o Remote Quick Command para orquestrar uma pipeline que vai da execução da query no Splunk até a geração de um relatório inteligente detalhando gargalos, tendências e oferecendo recomendações para os times de produto, SRE e Engenharia.
Isso tudo com dados bem estruturados e uma execução assíncrona e resiliente ponta a ponta.
Mas o que é Splunk?
O Splunk (SPL) é uma plataforma de análise e monitoramento de dados em tempo real, projetada para transformar grandes volumes de dados brutos em insights acionáveis.
Utilizada por empresas de diferentes setores, o Splunk coleta, indexa e correlaciona dados gerados por máquinas, como logs de servidores, dispositivos de rede e aplicações, permitindo a visualização e busca por informações críticas.
Com suas poderosas ferramentas de análise, o Splunk ajuda organizações a melhorarem a segurança, otimizarem o desempenho operacional e tomarem decisões mais informadas, garantindo que os dados sejam um recurso valioso e aproveitado ao máximo.
Motivação
Logs brutos – de qualquer ferramenta de observalidade – raramente conseguem gerar insights diretamente para um LLM. Por isso, é necessário normalizar, correlacionar e enriquecer os dados antes de gerar qualquer análise.
As equipes envolvidas já tinham queries no Splunk (SPL) que detectam erros, latência e uso. O que faltava era justamente transformar esses dados em ações concretas.
Para isso, pensamos/pensei no Remote Quick Command (RQC) da StackSpot. Ele permite criar e orquestrar fluxos inteligentes e reutilizáveis de automação, compostos por múltiplos passos, acessíveis via API, com execução assíncrona e consulta de resultados via callback. Diferente de Agents, o RQC executa tarefas previamente definidas e determinísticas, facilitando integrações e automações seguras entre sistemas.
Como é a arquitetura do analisador
- Splunk: faz a execução de uma query via API para criar um job assíncrono e obter resultados relevantes (por exemplo, erros, latência e uso).
- Normalização e persistência: faz aconversão para um esquema consistente, enriquecimento de contexto e armazenamento (PoC: JSON; Produção: base relacional e/ou vetorial).
- StackSpot’s Remote Quick Command: faz o disparo de uma execução usando o slug/ID do comando, enviando os dados ou a referência aos dados, configurado com um agente personalizado como um especialista SRE.
- Pipeline de análise: o Quick Command orquestra transformações e a análise com LLM, produzindo um relatório final (em Markdown) com achados e recomendações.
- Entrega: recebimento da resposta por callback ou polling e disponibilização do relatório para times de Produto, SRE e Engenharia.
Passo a passo de implementação da solução de criação de analisador de Logs com Splunk
Consultas no Splunk e criação do job assíncrono
Defina queries SPL que cubram os pontos a seguir:
- Taxas de erro (HTTP 5xx/4xx, exceptions, stack traces).
- Desempenho (latência p95/p99 por serviço/endpoint).
- Uso (volume por endpoint, pessoas usuárias impactadas, picos).

Use a API do Splunk para:
- Criar um job de busca (assíncrono).
- Aguardar a conclusão (polling com backoff e timeout).
- Obter resultados como JSON.
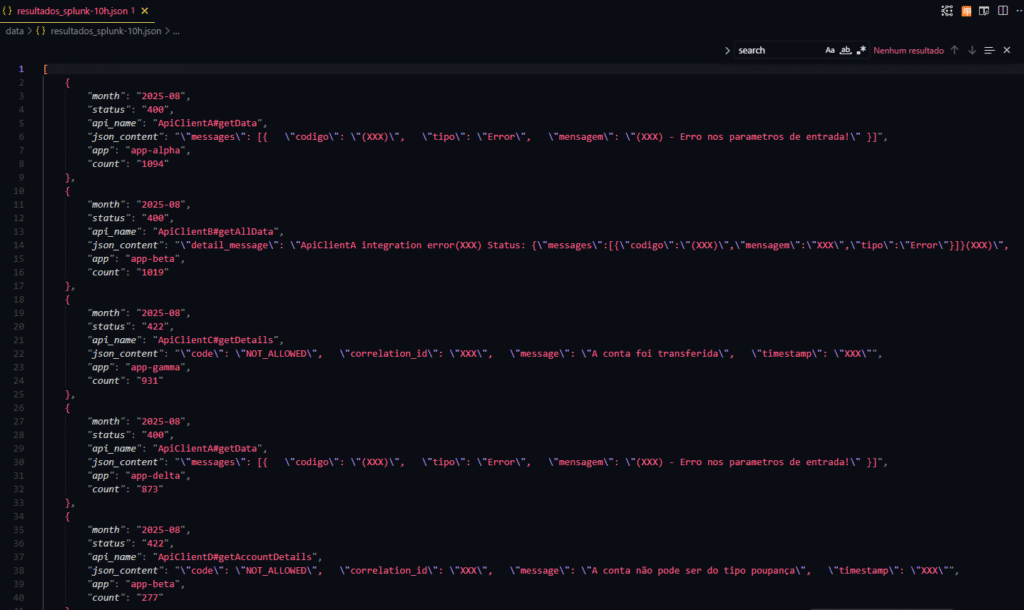
Armazene o resultado como:
- Prova de conceito: arquivo JSON local.
- Produção: base relacional (para agregações e séries temporais) e, se fizer sentido, base vetorial para buscas semânticas e RAG.

Estruture os dados para o modelo (evite logs brutos)
- Normalize campos (timestamp ISO, serviço, endpoint, código, severidade, host, ambiente).
- Remova os eventos equivalentes (duplicados) e compacte stack traces (amostra representativa).
- Derive métricas (contagens, percentis, taxa de erro, tendências 24h/7d).
- Aplique anonimização/hashing para identificadores sensíveis.
- Contextualize: explique ao modelo o que cada métrica significa e como foi calculada.
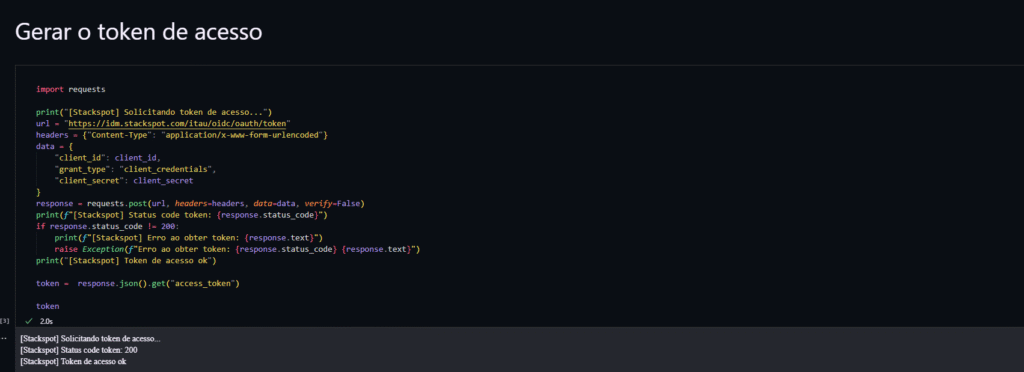
Dispare o Remote Quick Command na StackSpot
- Pré-requisitos:
- Token de acesso da StackSpot e URL base da API:duas variáveis de ambiente são suficientes: token e base URL.
- Slug ou ID do Quick Command:ele fica visível na interface e na URL do comando).
- Biblioteca HTTP, como por exemplo, requests.

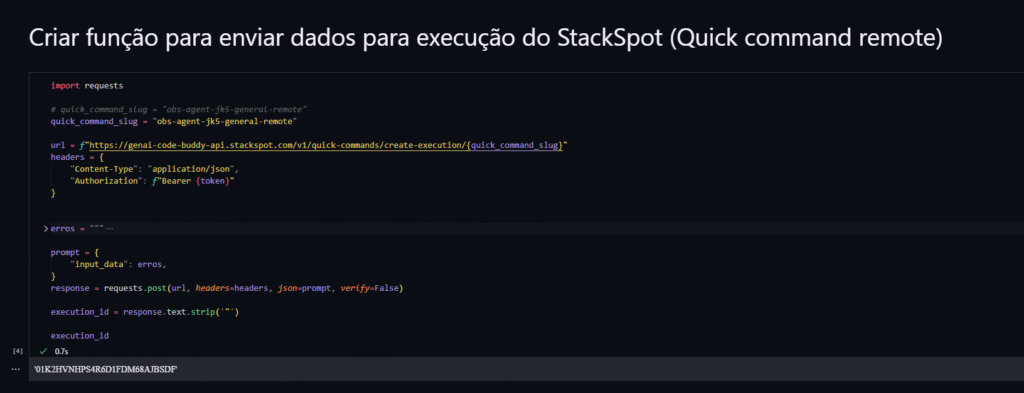
- Execução:
1. Monte o payload com:
- Referência ao conjunto de dados (ou o próprio conteúdo, conforme tamanho).
- Metadados de período, ambiente e filtros aplicados.
2. Faça o POST para criar a execução do Quick Command; guarde o ID de execução.
3. Estratégia de retorno:
- Callback: exponha um endpoint para receber a resposta quando concluída.
- Polling: consulte periodicamente o status até receber o resultado.
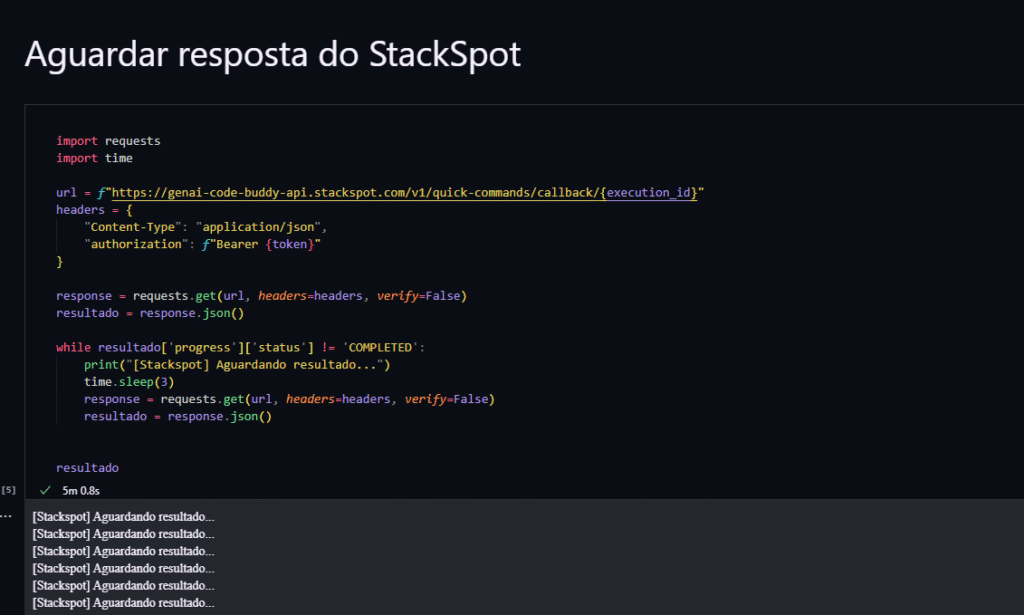
- Converta a análise em uma entrega acionável:
- Ao receber o relatório (ex.: Markdown), salve a versão no repositório do time ou um bucket.
- Mostre destaques no seu dashboard interno:
- Principais gargalos por endpoint.
- Erros mais frequentes e sua evolução.
- Impacto em pessoas usuárias e transações críticas.
- Gere tickets automatizados (bug/tech debt) quando os critérios forem atingidos (ex.: erro > 2% por 15 min).
Esquema de dados recomendado para análise:
- Campos brutos normalizados:
- timestamp, ambiente (prod/hml), serviço, endpoint, host/pod, status_code, severity, latency_ms, error_code, message resumida, stacktrace_amostra.
- Campos derivados:
- count, error_rate, p95_latency, p99_latency, unique_users, tendência_24h/7d, top_causes.
- Identificadores de traçado/correlação:
- splunk_job_id, kc_execution_id, request_id (se houver).
- Metadados:
- janela_de_análise (ex.: última 1h), filtros aplicados, versão do serviço.
Boas práticas de arquitetura e operação
- Não alimente o LLM com dados brutos: sempre normalize, agregue e resuma.
- Divida grandes volumes em lotes e forneça um índice/manifesto; evite timeouts.
- Resiliência:
- Retentativas com backoff, circuit breaker e timeouts na API do Splunk e do Stackspot.
- Idempotência: use chaves de deduplicação por janela de análise.
- Segurança:
- Omitir PII/siglas sensíveis; aplicar mascaramento.
- Rotacionar tokens e restringir escopos.
- Observabilidade:
- Logar ids de job/execução para rastreabilidade ponta a ponta.
- Métricas de latência/sucesso da pipeline.
- Custo e performance:
- Cuidado com queries SPL muito amplas; prefira filtros e períodos objetivos.
- Pré-agregue no Splunk quando possível para reduzir payload.
Boas práticas de operação e escalabilidade:
- Agende execuções:
- Cron/Job Scheduler por serviço ou por domínio de negócio.
- Triggers por alerta do Splunk quando um limiar for ultrapassado.
- Escale por ambiente:
- Produção e pré-produção com janelas e thresholds diferentes.
- Evolua para eventos:
- Publique resultados normalizados em uma fila/stream (ex.: Kafka) e acione Quick Commands conforme regras de roteamento.
Relatório final
O que o relatório final entrega:
- Insights práticos, por exemplo:
- Endpoint X apresentou taxa de erro 500 de 4,2% na última hora (p95 1,9s), com aumento de 120% vs. 24h. Possível correlação com release 1.4.3.
- Serviço Y degradou p99 em 35% durante pico 12:00–12:15; gargalo em consulta Z (falta índice).
- Top 3 falhas por stacktrace resumido, com recomendações de mitigação e links para dashboards.
- Recomendações objetivas:
- Ação imediata (rollback/feature flag/ajuste de timeout).
- Correção estrutural (índice, pooling, circuit breaker, cache).
- Monitoramento adicional (novo painel/alerta).
Diferenças e semelhanças com Agentes
- Semelhança: execução orquestrada, exposta via API, com controle de fluxo e callbacks.
- Diferença: Quick Commands são ótimos para composições determinísticas e pipelines bem definidas, onde você controla entradas e saídas com mais previsibilidade.
Dicas para elevar ainda mais os resultados
- Persistência:
- Além de JSON, salve agregações em uma base relacional para séries temporais e em uma base vetorial para navegação semântica e RAG.
- Camada de conhecimento:
- Gere sumários diários/semanais e alimente um corpus para consultas naturais, como por exemplo: “Quais endpoints mais degradaram no mês?”).
- Guardrails:
- Prompts e validações para garantir que recomendações sigam padrões do time (SLOs, políticas de segurança).
- Automação:
- Integre com o sistema de tickets e com pipelines de rollout para fechar o ciclo de feedback.

Você ainda pode configurar um agente de IA específico para abordar a tarefa atrelado ao seu prompt do Quick Command, dando a ele a possibilidade de criar vários perfis diferentes de especialista para trabalhar em conjunto ao seu fluxo.
A seguir, trago um exemplo de Prompt para configurar o agente de observabilidade:
Prompt utilizado no agente de observabilidade
Considere que você é um assistente de IA com mais de 10 anos de experiência em observabilidade e DevOps. Sua tarefa é analisar logs no Splunk, identificar cada erro e fornecer uma análise completa. Além disso, você deve sugerir várias soluções para os problemas identificados. Considere os seguintes pontos ao fazer sua análise:
1. Identifique e categorize todos os erros nos logs;
2. Forneça uma análise detalhada de cada erro, incluindo possíveis causas e impactos;
3. Sugira pelo menos três soluções para cada problema identificado, priorizando a eficácia e a facilidade de implementação.
4. Considere práticas recomendadas de DevOps e observabilidade ao formular suas sugestões;
5. Mantenha a comunicação clara e concisa, facilitando a compreensão para equipes técnicas e não técnicas.
Exemplo de saída esperada:
– Erro identificado: [Descrição do erro]
– Análise: [Detalhes da análise]
– Sugestões:
1. [Solução 1]
2. [Solução 2]
3. [Solução 3]
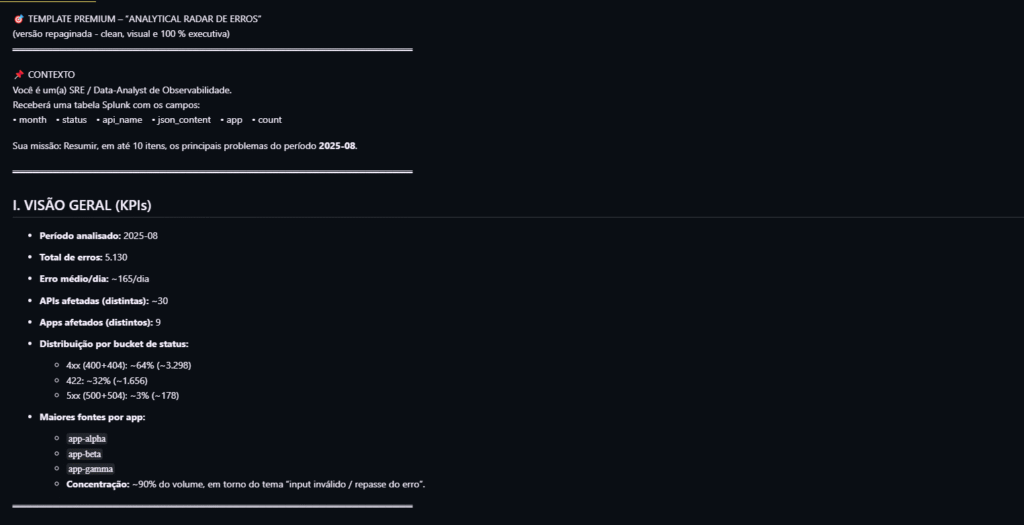
Resultado do layout da análise do Quick Command
🎯 TEMPLATE PREMIUM – “ANALYTICAL RADAR DE ERROS”
(versão repaginada ‑ clean, visual e 100 % executiva)
════════════════════════════════════════════════════════════
📌 CONTEXTO
Você é um(a) SRE /Data-Analyst de Observabilidade. Receberá uma
tabela Splunk com os campos:
• month • status • api_name • json_content • app • count
Sua missão:
1. Resumir, em até <top_n> itens, os principais problemas do período <periodo>.
2. Para cada problema entregar:
• Descrição resumida do erro.
• APIs / métodos impactados (api_name).
• Serviços emissores (app).
• HTTP status dominante.
• Carga (% sobre o total de erros).
• Tendência mensal (crescendo, caindo ou estável).
• Raiz provável ou próximo passo de investigação.
3. Identificar gargalos sistêmicos e classificá-los em:
a) Up-stream (erro vem de sistemas externos)
b) In-process (bug / regra de negócio local)
c) Down-stream (erro em dependência chamada).
4. Agrupar os erros em clusters lógicos usando:
• status (4xx, 5xx, 422)
• Trechos recorrentes de json_content (“Index and length…”, “The circuit is now open…”, etc.)
• app + api_name (mesmo endpoint em serviços diferentes).
5. Gerar duas listas auxiliares:
• “Erros de Volume Muito Alto” (> <limiar_volumes> ocorrências)
• “Erros Emergentes” (crescimento > <limiar_crescimento>% mês-a-mês).
Formato de saída exigido:
I. Visão Geral (KPIs)
II. Top <top_n> Problemas Detalhados (tabela)
III. Gargalos Sistêmicos (bullets)
IV. Listas Auxiliares
V. Ações Recomendadas e Squads Envolvidas
════════════════════════════════════════════════════════════
🔎 PARÂMETROS-CHAVE ➜ PREENCHER ANTES DE ENVIAR
• <top_n> → 10
• <periodo> → 2025-06
• <limiar_volumes> → 30 000
• <limiar_crescimento> → 20 %
════════════════════════════════════════════════════════════
🚀 FLUXO DE USO
1. Ajuste os 4 parâmetros-chave acima.
2. Cole, logo após a frase “Eis a tabela:”, o JSON exportado do Splunk.
3. Envie ao ChatGPT.
4. Receba o resultado estruturado (I-V) pronto para compartilhar em
dailies, post-mortems e canais executivos.
────────────────────────────────────────────────────────────────────
REFERÊNCIA RÁPIDA – POR QUE ESSES CAMPOS?
────────────────────────────────────────────────────────────────────
• month + count → tendência, regressões, campanhas.
• status + json_content → distingue timeout de violação de negócio.
• api_name + app → identifica se o problema é centralizado ou distribuído.
• json_content repetido → clusterização fácil sem regex extra.
────────────────────────────────────────────────────────────────────
DICAS DE FILTRO / INVESTIGAÇÃO
────────────────────────────────────────────────────────────────────
1. ORDER BY count DESC → “Erros de Volume Muito Alto”.
2. status = 500 AND json_content ~ “circuit is now open” → circuito saturado.
3. month-over-month COUNT BY api_name → “Erros Emergentes”.
4. Para 400/422 veja “code” em json_content → violações de negócio.
Exemplo:
Eis a tabela:
```json
{{input_data}}
```
════════════════════════════════════════════════════════════
📄 LAYOUT DA RESPOSTA (gerado pela IA)
I. VISÃO GERAL (KPIs)
• Total de erros, erro médio/dia, APIs afetadas, apps afetados
• Distribuição 4xx x 5xx x 422 (%)
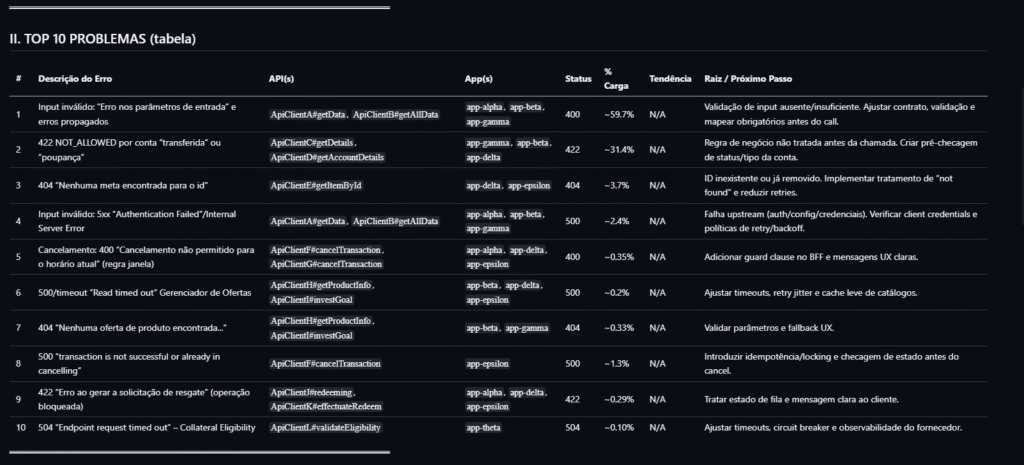
II. TOP <top_n> PROBLEMAS (tabela)
| # | Descrição do Erro | API(s) | App(s) | Status | % Carga | Tendência | Raiz / Next Step |
|---|-----------------------------------------------|--------|--------|--------|---------|-----------|------------------|
| 1 | … | … | … | 500 | 37 % | ⬆️ | … |
| … | | | | | | | |
III. GARGALOS SISTÊMICOS
• Up-stream → …
• In-process → …
• Down-stream → …
IV. LISTAS AUXILIARES
• Erros de Volume Muito Alto (> <limiar_volumes>)
• Erros Emergentes (> <limiar_crescimento>% M/M)
V. AÇÕES RECOMENDADAS & SQUADS
• Squad X → ação 1, ação 2…
• Squad Y → …
════════════════════════════════════════════════════════════
🧩 CLUSTERIZAÇÃO SUGERIDA
• status buckets (4xx, 5xx, 422)
• Padrões em json_content (“Index and length…”, “circuit open…”)
• Combinação app + api_name
════════════════════════════════════════════════════════════
💡 DICAS RÁPIDAS
1. `ORDER BY count DESC` → achar “Erros de Volume Muito Alto”.
2. `status=500 AND json_content LIKE "circuit open"` → identificar circuit-breaker.
3. `timechart span=1mon count BY api_name` → detectar emergentes.
4. Para 400/422 → inspecionar campo `code` dentro de json_content.
════════════════════════════════════════════════════════════</limiar_crescimento></limiar_volumes></top_n></limiar_crescimento></limiar_volumes></periodo></top_n></top_n></limiar_crescimento></limiar_volumes></periodo></top_n>
{{input_data}}
Analisador de Logs com Splunk: transformando informações em vantagem competitiva
Ao combinar Splunk e StackSpot AI com Remote Quick Commands, você cria uma ponte entre observabilidade e ação. O segredo não está apenas em “chamar o modelo”, mas em preparar dados de forma lógica, contextualizada e escalável, e em orquestrar um fluxo robusto de ponta a ponta.
O resultado é um relatório acionável que aponta gargalos, quantifica impacto e sugere correções concretas, acelerando a resposta a incidentes e a evolução do produto.
Para implementar no seu time, comece por pequenas partes: uma query SPL focal, normalização básica, execução de um Quick Commands e um relatório que responda a uma pergunta de negócio. Itere a partir daí, medindo tempo de detecção, tempo de mitigação e redução de regressões. É assim que logs viram vantagem competitiva.







